For future reference, this was resolved like this:
The first and actual error message you get in DocumentViewer is “bad allocation” with clean DocumentCache folder.
So it's possibly about insufficient memory.
An exception of type 'System.Runtime.InteropServices.SEHException' occurred in NativeDocumentEngine.dll and wasn't handled before a managed/native boundary
Additional information: External component has thrown an exception.
So something went wrong during conversion of the file to the special web-friendly format XPZ.
After this error occurs, on your second viewing of the page you start getting javascript errors, these errors are caused because the XPZ file is 0-byte as the conversion failed. Normally with other type of exceptions 0-byte will be deleted automatically but
SEHException is a special exception (caused by native DLL) so it's not caught by .NET and as a result the empty file is not deleted from cache.
To fix it:
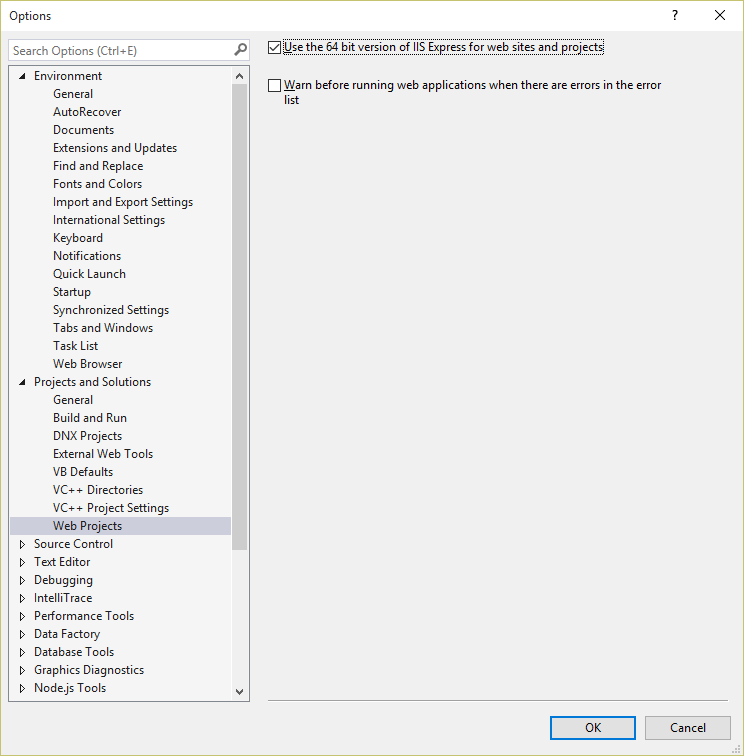
- You need to enable 64-bit mode of IIS Express in Visual Studio Options
When you launch a web project in Visual Studio, by default is uses the 32-bit version of IIS Express. To change that you can enable the 64-bit version through Options.
So, head to:
• Tools
• Options
• Project and Solutions
• Web Projects and check the option
• “Use the 64 bit version of IIS Express for web sites and projects”
Screenshot:
- Before you try again make sure you delete contents of App_Data\DocumentCache folder (or only delete the corresponding cache file).
Once the conversion is failed you will have 0-byte XPZ cached file and this will keep you giving javascript errors which are not the main problem they are the result of first error.
After enabling IIS Express 64-bit mode and started debugging with a clean DocumentCache, I was able to display your test.pdf without any problems.
More information:
- I also use IIS Express with default 32-bit mode on my machine, for example with my sample empty projects the error does not happen. I think only when you add Telerik stuff and use IIS Express 32-bit mode, the error happens. However when you use IIS Express 64-bit mode, all libs live happily
- I will investigate further why the error happens with Telerik and IIS Express 32-bit combined.
However there is no disadvantage to use IIS Express 64-bit, actually it’s better from memory perspective so you can consider it fixed. 64-bit can handle more than 2GB process memory so the problem seems to be about memory. Probably Telerik also uses a lot of memory and there there is not enough left for DocumentUltimate to successfully convert complex PDF documents. Note that I am talking about max memory that a process can use, that’s 2GB for 32-bit, even if you have 16GB in your machine 32-process will not be able to use more than 2GB.